La verdad es que cuando comenzamos a crear nuestro primer ETL con Hadoop, las primeras herramientas que analizamos trabajaban sobre MapReduce, y cuando dije que trabajaban, digo que no se podía utilizar otra herramienta [más adelante, se pudo cambiar, pero en aquel momento no]. Hive, Sqoop, etc.. todas ellas, trabajaban exclusivamente con MapReduce.
Obviamente MapReduce era un motor increíble de computación, con varios años en sistemas de producción, y eso da estabilidad. Y a los arquitectos de sistemas, eso nos encanta… bueno, a los arquitectos de sistemas poco atrevidos.
En aquel momento, llegó a mis oídos una nueva herramienta, un motor de procesamiento que se suponía que era mucho más rápido que MapReduce, un sistema que prometía tanto que obviamente creó un gran revuelo. Y todos los benchmark que leía, no hacían más que confirmarlo. ¿Adivinas qué es lo que hice?
Lo primero que hice fue instalarlo en mi sistema de pruebas. Conocía todos los requisitos, ya que había leído que, como el Google Chrome actual [el de 2019, por supuesto], consumía memoria que daba gusto [vamos un vampiro] y no me equivoqué. El sistema de pruebas se quedó sin memoria en poco tiempo, con un dataset pequeño, mientras que el mismo dataset pudo ser computado sin problemas con MapReduce, en el mismo sistema.
Así que indagué en la arquitectura de MapReduce y en la arquitectura de Spark, y entendí el porqué uno era lento, pero confiable y llevaba mucho tiempo en producción, y otro era muy rápido.
MapReduce es un sistema que en cada iteración de computación almacena en disco duro el resultado, esto permite tener un sistema confiable y resistente a fallos.
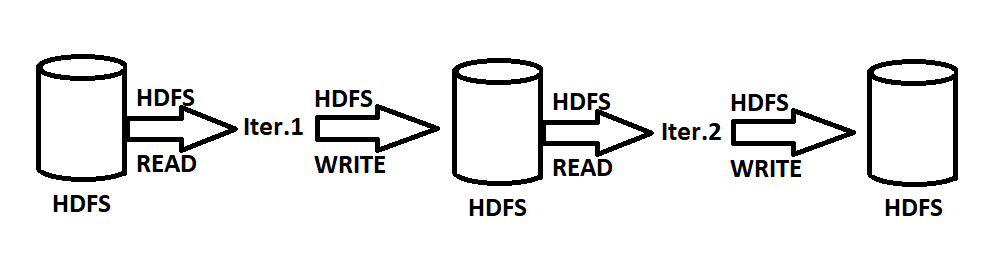
Spark por el contrario almacena en cada iteración de computación el resultado en memoria en RDD, lo que permite tener un sistema de rápido acceso a los resultados y una computación rapidísima, ya que se elimina el delay de acceso a disco duro.
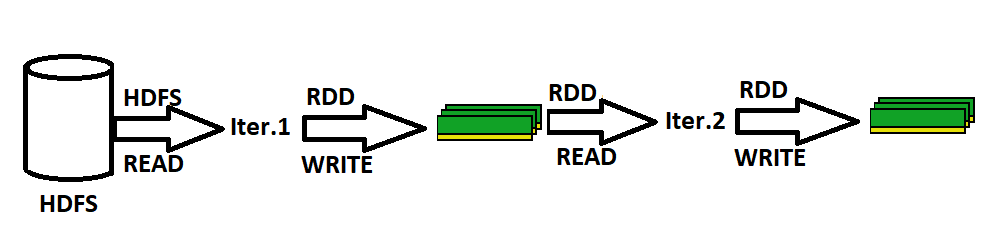
Seguramente, ya has notado porque es más rápido, no es por los algoritmos solamente, sino por el consumo de memoria. Esto realmente es increíble para el procesamiento en tiempo real, y de hecho es para lo que lo utilizamos, pero, imagina que tienes un cluster solo con Spark, has de saber que toda la memoria va a ser consumida por Spark, como si no hubiera mañana. Y claro está, la memoria es muchísima más costosa que el disco duro.
Así pues, nosotros al utilizar una arquitectura Lambda en ese momento [no te preocupes, lo explicaré en otra entrada], utilizamos Spark en la parte de procesamiento de tiempo real, pero seguíamos utilizando MapReduce en la parte de procesamiento batch, ya que MapReduce es bastante estable… y porque Hive era el motor que utilizábamos en la parte de batch.
Resumiendo, en mi experiencia, sé que en 2019, no hay mucho que decir entre MapReduce y Spark, Spark es una herramienta muy utilizada en casi todos los pipeline de procesamiento, sobre todo por la arquitectura Kappa utilizada por las empresas, pero, también he de decir, que llevo utilizando herramientas como Hive o Sqoop con MapReduce años, y nunca he tenido problemas, en serio, ningún tipo de problema, pero cuando he cambiado en Hive el motor, y he utilizado ORC, Spark u otra herramienta de procesamiento, he encontrado problemas que con MapReduce no he tenido.
Si quieres hacerme un comentario, no dudes en seguirme o hacerme un comentario referenciándome a Rafael Piernagorda
¿Te gustaría saber cómo podría encajar Hadoop con tu proyecto?
Contacta con nosotros y te ayudaremos con tu proyecto de Hadoop